本文首先介绍Springboot的单数据源配置方式,并介绍其中的Springboot自动装配细节;其次介绍如何配置多数据源。
单数据源配置
得益于Springboot的自动装配,在Springboot中使用Mybatis连接mysql等数据库非常方便,大概只需要两步:
- 在yaml文件中配置
spring.datasource.xx,用来定义datasource,包括driver class、url、用户名、密码等 - 在yaml文件中配置
mybatis.xx,用来修改Mybatis的默认参数。下面是一个例子:
spring:
datasource:
url: jdbc:mysql://xxxxxx:3306/database?useUnicode=true&characterEncoding=utf-8&useSSL=true&autoReconnect=true
username: xxx
password: xxxxx
driver-class-name: com.mysql.jdbc.Driver
mybatis:
configuration:
map-underscore-to-camel-case: true # 将数据库下划线字段,映射为Java的驼峰式Field。很方便,这样就省去了ResultMap中字段映射
type-handlers-package: com.arloor.mybatis.typehandler # 数据库类型到Java类型的映射
自动装配实现
自动装配的核心类是 MybatisAutoConfiguration,先看这个类上重要的三个注解:
@ConditionalOnSingleCandidate(DataSource.class)
@EnableConfigurationProperties(MybatisProperties.class)
@AutoConfigureAfter({ DataSourceAutoConfiguration.class, MybatisLanguageDriverAutoConfiguration.class })
| 注解 | 含义 |
|---|---|
| @ConditionalOnSingleCandidate(DataSource.class) | 当只有一个DataSource的bean时生效。如果有多个Datasource的bean,但其中一个被@Primary注解时,同样认为生效 |
| @EnableConfigurationProperties(MybatisProperties.class) | 启用MybatisProperties,读取 mybatis.xxx 的配置 |
| @AutoConfigureAfter({ DataSourceAutoConfiguration.class, MybatisLanguageDriverAutoConfiguration.class }) | 触发Datasource的自动装配,从 spring.datasource.xx 读取配置 |
再看 MybatisAutoConfiguration 到底做了啥,截取下其中几个bean定义就很清楚了,直接以一段代码展示吧。
// 从唯一的或者@Primary的Datasource bean创建SqlSessionFactory bean
@Bean
@ConditionalOnMissingBean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception
// 如果没有SqlSessionTemplate的bean,则创建。有一说一,SqlTemplate用的不多
@Bean
@ConditionalOnMissingBean
public SqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactory)
/**
* If mapper registering configuration or mapper scanning configuration not present, this configuration allow to scan
* mappers based on the same component-scanning path as Spring Boot itself.
*/
// 如果没有使用@MapperScan或其他方式来定义mapper接口所在地,则扫描@Mapper注解的接口
@org.springframework.context.annotation.Configuration
@Import(AutoConfiguredMapperScannerRegistrar.class)
@ConditionalOnMissingBean({ MapperFactoryBean.class, MapperScannerConfigurer.class })
public static class MapperScannerRegistrarNotFoundConfiguration implements InitializingBean
多数据源配置
MapperScan.class 的java Doc就定义了一个完整的数据源——datasource + sqlSessionFactory + MapperScan。而多数据源配置就是多组 datasource + sqlSessionFactory + MapperScan。下面的代码就定义了 com.arloor.one.mapper 走 oneSessionFactory,com.arloor.two.mapper 走 twoSessionFactory。
@Configuration
@MapperScan(value = "com.arloor.one.mapper", sqlSessionFactoryRef = "oneSessionFactory")
public class OneConfig {
@Bean("oneSource")
public DataSource dataSource() {
return ....;
}
// @Bean
// public DataSourceTransactionManager transactionManager() {
// return new DataSourceTransactionManager(dataSource());
// }
@Bean("oneSessionFactory")
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(dataSource());
// 省略很多其他配置,例如xml文件所在位置
return sessionFactory.getObject();
}
}
@Configuration
@MapperScan(value = "com.arloor.two.mapper", sqlSessionFactoryRef = "twoSessionFactory")
public class TwoConfig {
@Bean("twoSource")
public DataSource dataSource() {
return ....;
}
@Bean("twoSessionFactory")
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(dataSource());
// 省略很多其他配置,例如xml文件所在位置
return sessionFactory.getObject();
}
}
其他主题
- 多数据源下定义
DataSourceTransactionManager,以实现事务管理 - 在使用MybatisAutoConfiguration的项目中,增加数据源。或者说,自动装配数据源和其他数据源共存。估计是使用@Primary的注解,目前不确定的是@Mapper的类会走哪个数据源,遇到再做学习。
- 数据库连接池使用。本质挺简单,就是个装饰器模式或者代理模式,使用上还不熟练。
自定义TypeHandler
MySQL的字段还是比较简单,Clickhouse就有很多类型了,比如groupArray等等,这种就需要自定义typeHandler了,这里记录下相关代码。需要注意的是,下面代码使用了深拷贝,原因是clickhouse的ResultSet会复用对象(举个例子:A本来是第一行的数据,到第二行变成了第二行的数据)
import com.arloor.GroupArray;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedTypes;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@MappedTypes({GroupArray.class})
// @MappedJdbcTypes({JdbcType.ARRAY}) // 如果加了这个,则只对该种类型的数据库字段生效。不加则对所有类型的数据库字段生效
public class GroupArrayTypeHandler extends BaseTypeHandler<GroupArray> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, GroupArray parameter, JdbcType jdbcType) throws SQLException {
ps.setObject(i, parameter);
}
@Override
public GroupArray getNullableResult(ResultSet rs, String columnName) throws SQLException {
String[][] ckBuffer = (String[][]) rs.getObject(columnName);
String[][] result = deepClone(ckBuffer);
return new GroupArray(result);
}
@Override
public GroupArray getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
String[][] ckBuffer = (String[][]) rs.getObject(columnIndex);
String[][] result = deepClone(ckBuffer);
return new GroupArray(result);
}
private static String[][] deepClone(String[][] ckBuffer) {
String[][] result = new String[ckBuffer.length][];
for (int i = 0; i < ckBuffer.length; i++) {
result[i]=new String[ckBuffer[i].length];
for (int j = 0; j < ckBuffer[i].length; j++) {
result[i][j]= ckBuffer[i][j];
}
}
return result;
}
@Override
public GroupArray getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
String[][] ckBuffer = (String[][]) cs.getObject(columnIndex);
String[][] result = deepClone(ckBuffer);
return new GroupArray(result);
}
}
import com.arloor.type.StringArray;
import org.apache.commons.lang3.StringUtils;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import org.apache.ibatis.type.MappedTypes;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
@MappedTypes({List.class})
@MappedJdbcTypes({JdbcType.ARRAY})
public class ClickArrayListTypeHandler extends BaseTypeHandler<List<String>> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, List<String> parameter, JdbcType jdbcType) throws SQLException {
if (jdbcType == null || StringUtils.isEmpty(jdbcType.name()) || jdbcType.name().equals("VARCHAR")) {
ps.setArray(i, new StringArray(parameter.toArray(new String[0])));
} else {
ps.setArray(i, ps.getConnection().createArrayOf(jdbcType.name(), parameter.toArray(new String[0])));
}
}
@Override
public List<String> getNullableResult(ResultSet rs, String columnName) throws SQLException {
Object array = rs.getArray(columnName).getArray();
if (array instanceof List){
return new ArrayList<>((List) rs.getArray(columnName).getArray());
} else {
return new ArrayList<>(Arrays.asList((String[]) rs.getArray(columnName).getArray()));
}
}
@Override
public List<String> getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return new ArrayList<>(Arrays.asList((String[]) rs.getArray(columnIndex).getArray()));
}
@Override
public List<String> getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return new ArrayList<>(Arrays.asList((String[]) cs.getArray(columnIndex).getArray()));
}
}
其中StringArray类也挺有意思的,大家应该知道Mysql是没有Array类型的,但Clickhouse有该类型。原生的创建array的方式如下:
statement.getConnection().createArrayOf("VARCHAR", item.getApps().toArray(new String[0]))
完整代码:
try (Connection connection = clickhouseDataSource.getConnection()) {
try (PreparedStatement statement = connection.prepareStatement(INSERT_STATEMENT)) {
for (TraceIdIndexItem item : buffer.values()) {
statement.setString(1, item.getTraceId());
statement.setTimestamp(2, new Timestamp(item.getTraceIdTime().getTime()));
statement.setArray(3, statement.getConnection().createArrayOf("VARCHAR", item.getApps().toArray(new String[0])));
statement.setObject(4, item.getMinStartTimestampMicros());
statement.setObject(5, item.getMaxStartTimestampMicros());
statement.setInt(6, item.getError());
statement.addBatch();
}
statement.executeBatch();
exception = null;
} catch (Exception e) {
exception = e;
}
}
这里存在的问题是,createArrayOf需要创建连接,性能非常差,在火焰图上可以看出来。因此,自定义了一个StringArray类,并实现了 java.sql.Array 的相关接口,代码如下:
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.sql.Types;
import java.util.Map;
public class StringArray implements java.sql.Array {
private String[] data;
public StringArray(String[] data) {
this.data = data;
}
@Override
public String getBaseTypeName() throws SQLException {
return "VARCHAR";
}
@Override
public int getBaseType() throws SQLException {
return Types.VARCHAR;
}
@Override
public Object getArray() throws SQLException {
return data;
}
@Override
public Object getArray(Map<String, Class<?>> map) throws SQLException {
return data;
}
@Override
public Object getArray(long index, int count) throws SQLException {
throw new SQLFeatureNotSupportedException("getArray");
}
@Override
public Object getArray(long index, int count, Map<String, Class<?>> map) throws SQLException {
return getArray(index, count);
}
@Override
public ResultSet getResultSet() throws SQLException {
throw new SQLFeatureNotSupportedException("getRuleSet");
}
@Override
public ResultSet getResultSet(Map<String, Class<?>> map) throws SQLException {
return getResultSet();
}
@Override
public ResultSet getResultSet(long index, int count) throws SQLException {
return getResultSet();
}
@Override
public ResultSet getResultSet(long index, int count, Map<String, Class<?>> map) throws SQLException {
return getResultSet();
}
@Override
public void free() throws SQLException {
this.data = null;
}
}
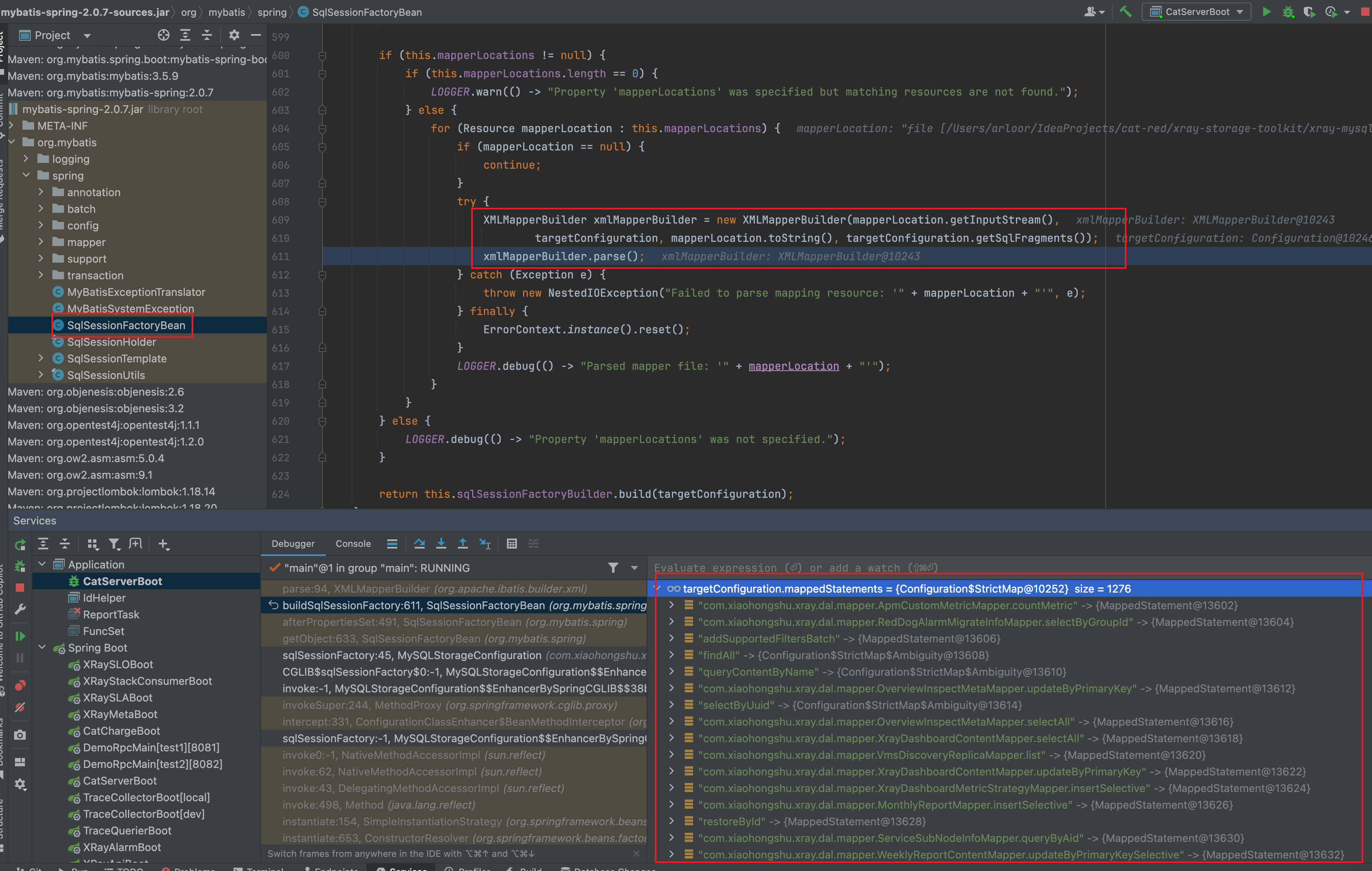
Debug:找不到Mapperstatement
Caused by: org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): com.xxx.xxx.xxx.xx.dal.mapper.ZoneEnumMapper.selectAll
at org.apache.ibatis.binding.MapperMethod$SqlCommand.<init>(MapperMethod.java:235)
at org.apache.ibatis.binding.MapperMethod.<init>(MapperMethod.java:53)
at org.apache.ibatis.binding.MapperProxy.lambda$cachedInvoker$0(MapperProxy.java:108)
at java.util.concurrent.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1660)
at org.apache.ibatis.util.MapUtil.computeIfAbsent(MapUtil.java:35)
at org.apache.ibatis.binding.MapperProxy.cachedInvoker(MapperProxy.java:95)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
at com.sun.proxy.$Proxy115.selectAll(Unknown Source)
..............
关键方法:
org.mybatis.spring.SqlSessionFactoryBean#buildSqlSessionFactory // 创建SqlSessionFactory
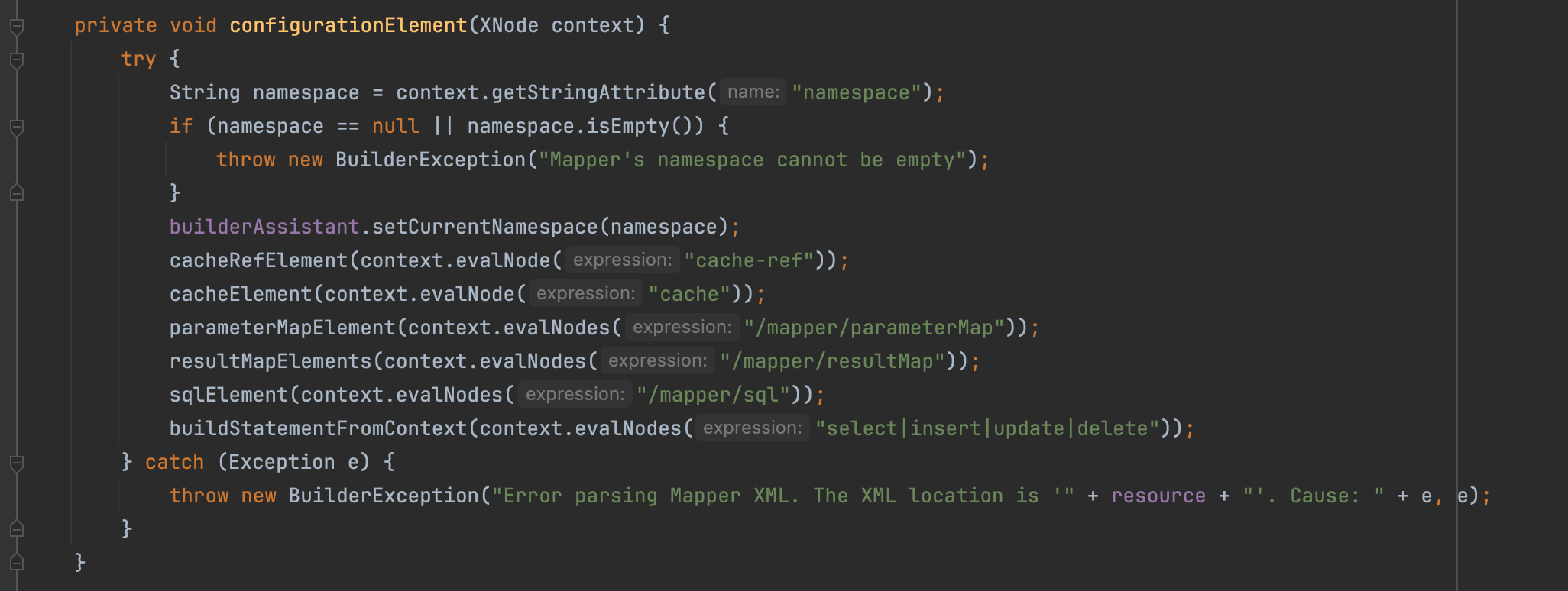
org.apache.ibatis.builder.xml.XMLMapperBuilder#parse // 解析xml
org.apache.ibatis.builder.xml.XMLMapperBuilder#configurationElement //解析BaseReusltMap 和 sql等