
Entry级别拓扑及性能指标计算
背景
上下游拓扑及上下游调用性能指标是链路监控的重要部份。从生成过程来看,先给trace个案进行分类,然后按类汇总出同类trace的调用路径,这个调用路径通常是一个有向无环图,也就是拓扑。按照什么标准进行分类是上述过程的重点,上面所说的分类和汇总,表述成SQL大概就是聚合函数(count、avg等)和groupBy语句的结合,其中groupBy语句就是分类标准, count和avg是相关的性能指标。
select count(xx), avg(yy) from data_source where .... group by zz
目前大多数的开源产品和商业产品所提供的拓扑分析功能,都是如实地记录某RPC节点的上游和下游,这像是架构图中的物理视图,在描述一种物理的存在和组织形式。就像使用逻辑视图来补充物理视图一样,用户真正需要的拓扑分析往往不限于描绘一种物理的调用关系,还需要描绘某一个业务场景下的的上下游关系,这些上下游调用关系共同完成了某一个具体的业务功能,例如订单、商品等。
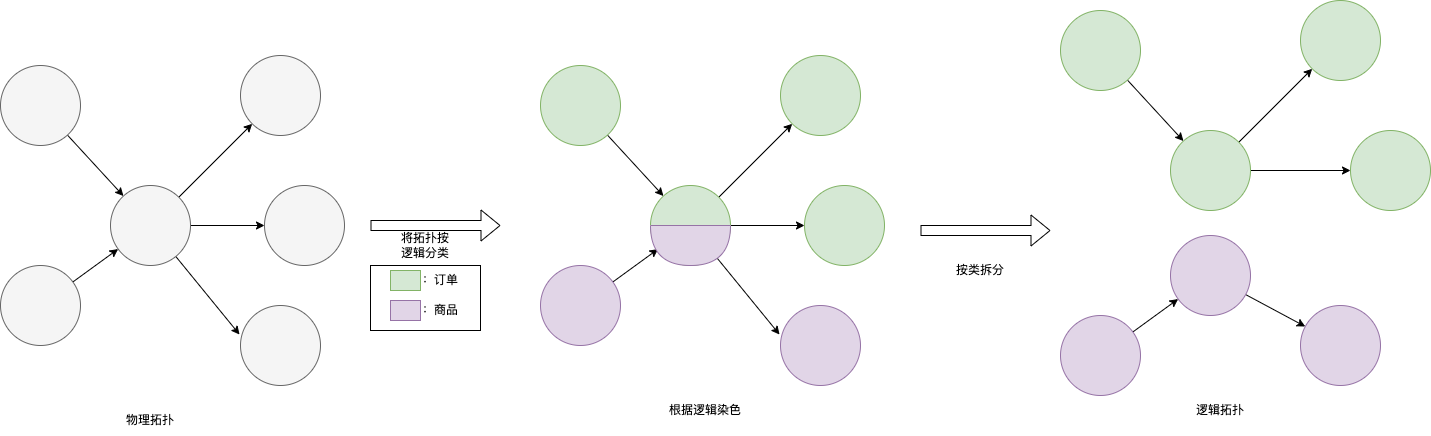
从物理上的拓扑到逻辑上拓扑的演变,从实现上来讲就是细化分类标准。之前,同事已经提出了场景和Entry(入口)的概念:Entry是某个trace起点的RPC Service或HttpURL;场景则是多个Entry的集合,比如下单场景就会有多个不同的入口。场景和Entry本身是有业务含义的,我们要做的是以场景和Entry作为分类标准,生成拓扑图和上下游调用性能指标。考虑到,场景是多个Entry的集合,所以我们先做Entry级别的拓扑,而后通过聚合Entry下的数据生成场景级别数据。
目标
1. 以Entry作为分类标准,生成Entry下的拓扑
2. 根据采样率估算Entry拓扑下各个RPC调用的R.E.D指标
下面的详细方案部份也将分为两个部份描述,先描述Entry下的拓扑,再描述RPC调用的R.E.D指标生成。
详细方案
协议
先从tracing的ProtoBuf协议入手,该方案需要用到的字段有:
// 用于生成拓扑
string entry = 12; // 入口名
string parent_app = 4; //父app
string parent_rpc_service_name = 7;//父RPC Service名
// 用于还原性能指标
int32 samplingStrategy = 11;// 采样策略的flag,用来判断是否可以用于还原性能指标
double sampleRatio = 14; // 采样率
int64 duration_micros = 7; // 耗时,用于还原平均耗时
bool error = 8; // 状态,用于还原总失败率
其中,entry、parent_app、parent_rpc_service_name用于生成拓扑,sampleRatio、duration_micros、error用于还原性能指标(次数、耗时、错误率)。
架构
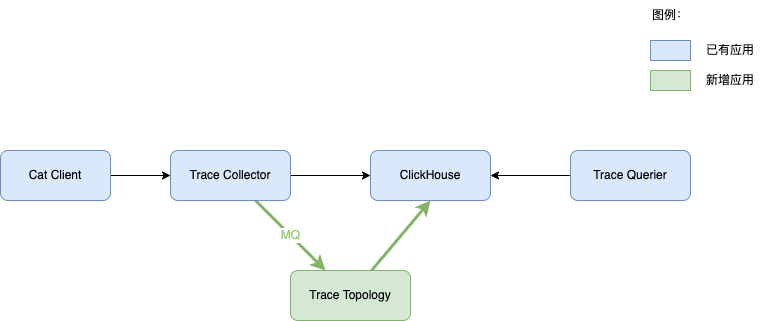
增加Trace Topology应用,使用MQ与Trace Collector解耦。
方案简介
在后端接收到Segment时进行实时聚合,以entry作为标签,生成上下游调用拓扑和上下游调用性能指标。
性能指标:
TraceCollector接收到Segment后,通过时间窗口聚合出性能指标,次数、失败数、耗时指标的Metric Name分别为:
● ${entry}${parent}${son}_count
● ${entry}${parent}${son}_error
● ${entry}${parent}${son}_duration
前缀部分的${entry}${parent}${son}标明这是哪个entry下哪个上下游调用的。
tag为/traceCollector=${collectorNode},标明这是哪个traceCollector实例上报的指标,因为traceCollector的机器数量有限,所以这个tag是低基数的。
因为trace是采样的,所以计算性能指标时需要通过采样率进行估算和还原。方式也比较简单,例如收到一个span的采样率为0.1,那么可以推算,实际上发生了10条相同的span。
如果Prometheus不能存储上面的指标,也可以使用ClickHouse存储。主键设计为:
order by entry, parent, son
依赖拓扑:
性能指标名其实已经包含了生成拓扑的足够信息,如果Prometheus能提供scan by prefix的能力,我们可以查询出所有以${entry}开头的指标名,然后解析${parent}${son},将所有${parent}${son}的汇总,即得到该${entry}下的完整依赖拓扑。
如果不能通过Prometheus达到以上目的,将存储${entry}${parent}${son}在mysql或者redis,一样可以根据${entry}拿到所有的${parent}_${son},而后进行依赖拓扑聚合。
详细方案
由于Entry下的性能指标作为时间线的话会有很多,一个入口就可能产生成千上万的时间线,所以并不适合存储在Pronmetheus中,我们选取ClickHouse作为存储。接下来先从查询需求入手确定ClickHouse表结构设计,再介绍Trace Topology的实现。
拓扑查询写成sql的格式可以表述为:
select
distinct entry, upstream_app,upstream_service, downstream_app, downstream_service
from RPC_statistics
where entry = 'xxxx' and time >= 'xx' and time < 'xx'
该查询结果集的每一行都是拓扑图中的一条边,将该结果集以邻接矩阵或者邻接表的格式传递给前端即可绘制出完成的拓扑图。
性能指标查询写成sql可以表述为:
WITH 1 as interval,
select
sum(count) as total,
sum(total_duration)/sum(count) ag avg,
max(max_duration) as max,
sum(error) as error_total,
toStartOfInterval(`time`, INTERVAL interval minute) AS data_time,
from RPC_statistics
where entry = 'xxxx' and time >= 'xx' and time < 'xx'
group by data_time, upstream_app,upstream_service, downstream_app, downstream_service
order by data_time asc;
该查询的结果集的一行是某分钟的RED指标。
结合上述的查询需求,最终的ClickHouse表可以设计为:
CREATE TABLE RPC_statistics (
"entry" String Codec(?CODEC),
"downstream_app" LowCardinality(String) Codec(?CODEC),
"downstream_service" String Codec(?CODEC),
"upstream_app" LowCardinality(String) Codec(?CODEC),
"upstream_service" String Codec(?CODEC),
"time" DateTime Codec(Delta, ?CODEC),
"count" Float64 Codec(DoubleDelta, ?CODEC),
"total_duration" Float64 Codec(DoubleDelta, ?CODEC),
"max_duration" Float64 Codec(DoubleDelta, ?CODEC),
"error" Float64 Codec(DoubleDelta, ?CODEC),
"create_time" DateTime Codec(Delta, ?CODEC),
"report_node" LowCardinality(String) Codec(?CODEC) /*上报此数据的机器*/,
)
ENGINE = ?(REPLICATED)MergeTree()
ORDER BY (entry, downstream_app, downstream_service, upstream_app, downstream_service)
PARTITION BY toDate("time")
TTL toDate("time") + INTERVAL ?TTL DELETE
SETTINGS ttl_only_drop_parts = 1
其中有几个点需要特别说明下:
● report_node 用于标记是哪台机器上报。
● total_duration 用于计算出准确的avg信息,避免avg的avg不准确,或者sum(count*duration)这样需要不同列进行计算的性能差的情况。
Trace Topology的实现示意图如下:
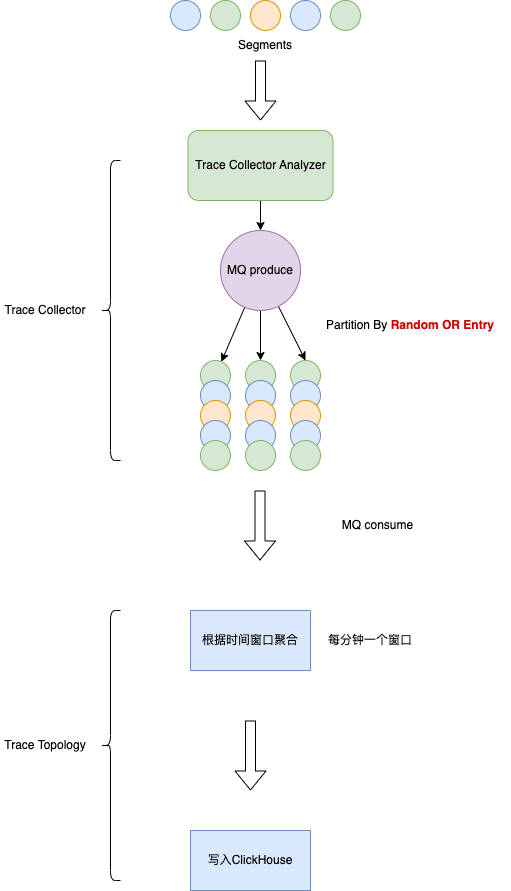
其中有一个关键在于,MQ生产时的partKey是随机还是Entry,是否要将相同的entry路由到相同的机器上?优劣对比如下:
| 方案 | 根据Entry路由 | 随机路由 |
|---|---|---|
| 优势 | 1. 同类数据路由在同一机器上。统计性能指标时不需要将CK中不同机器上报的数据加和。 | 1. 完全随机,分片肯定均衡,不会存在热点问题。 |
| 劣势 | 1. 可能存在热点问题 | 1. 统计性能指标时需要将CK中不同机器上报的数据加和。 |
还需要考虑,根据Entry路由的话,性能指标统计的SQL中是否还要对count、duration等做sum、avg等聚合函数?答案是,需要做聚合,因为可能存在trace数据的延迟上报,需要聚合来将同一分钟的数据整合。
方案执行
实际执行中,直接使用ClickHouse的SummingMergeTree进行相关的聚合而不是新增Trace Topology进行内存中聚合。也有文章提到SummingMergeTree是时序数据最合适的表引擎,链接:Improve performance with time series data | ClickHouse Knowledge Base (tinybird.co)。
drop TABLE if exists RPC_statistics on cluster default_cluster;
CREATE TABLE if not exists RPC_statistics on cluster default_cluster
(
`entry` String,
`time` DateTime,
`downstream_app` LowCardinality(String),
`downstream_service` String,
`upstream_app` LowCardinality(String),
`upstream_service` String,
`count` Float64,
`total_duration` Float64,
`max_duration` SimpleAggregateFunction(max, Int64),
`error` Float64,
`examplar` String,
INDEX idx_downstream_app downstream_app TYPE bloom_filter GRANULARITY 4,
INDEX idx_upstream_app upstream_app TYPE bloom_filter GRANULARITY 4,
PROJECTION p_downstream_app_entry
(
SELECT
downstream_app,
downstream_service,
groupUniqArray(`entry`) as entryList
group BY
downstream_app,downstream_service
)
)
ENGINE = SummingMergeTree
PARTITION BY toDate(time)
PRIMARY KEY (entry, time)
ORDER BY (entry, time, downstream_app, upstream_app, downstream_service, upstream_service)
TTL toDate("time") + toIntervalDay(1) TO DISK 'hdd',toDate("time") +toIntervalDay(21)
settings storage_policy = 'ssd_hdd_cos';
drop table if exists RPC_statistics_distributed on cluster default_cluster;
CREATE TABLE if not exists RPC_statistics_distributed on cluster default_cluster
(
"entry" String,
"time" DateTime,
"downstream_app" LowCardinality(String),
"downstream_service" String,
"upstream_app" LowCardinality(String),
"upstream_service" String,
"count" Float64,
"total_duration" Float64,
"max_duration" SimpleAggregateFunction(max,Int64),
"error" Float64,
"examplar" String ---- 生成该指标的traceId
)
ENGINE = Distributed('default_cluster', 'cat', 'RPC_statistics', rand());
核心是
- 使用SummingMergeTree表引擎对count、total、error进行自动的求和。
- 对于max_duration需要求最大的需求,使用SimpleAggregateFunction类型来做。SimpleAggregateFunction类型相比AggregateFunction类型更simple体现在三点(详见:SimpleAggregateFunction | ClickHouse Docs和AggregateFunction(name, types_of_arguments…) | ClickHouse Docs)
- 不需要使用-State或-Merge的后缀
- 不需要结合物化试图
- 可以使用简单的insert into语句,而不需要使用insert select
- 仅支持部分聚合函数
- count、total_duration、error使用double类型,因为原始值除以采样率后是浮点数。
- examplar是生成该指标的traceId。在SummingMergeTree中,无法聚合的字段会选取第一个写入的值,也满足我们保留一个例子的需求。
- 创建了根据下游app寻找对应entry的projection。
查询Service级别性能指标:
SELECT
downstream_app,
upstream_app,
sum(count) AS total,
sum(total_duration) / sum(count) AS avg_duration,
max(max_duration) AS max_duration,
sum(error) AS error,
min(examplar) AS examplar
FROM RPC_statistics_distributed
where entry in ('http://www.xiaohongshu.com/api/store/jpd/claim')
and time BETWEEN '2023-04-25 10:00:00'
and '2023-04-25 12:00:00'
GROUP BY
downstream_app,
upstream_app,
downstream_service,
upstream_service
SETTINGS allow_experimental_projection_optimization = 0,
force_index_by_date=1; --- 不使用上面的projection
查询App级别性能指标:
select downstream_app,
upstream_app,
sum(count) as total,
sum(total_duration) / sum(count) as avg_duration,
max(max_duration) as max_duration,
sum(error) as error
from RPC_statistics_distributed
where entry in ('http://www.xiaohongshu.com/api/store/jpd/claim')
and time BETWEEN '2023-04-25 00:00:00'
and '2023-04-26 00:00:00'
group by downstream_app, upstream_app
settings allow_experimental_projection_optimization=0; --- 不使用上面的projection
聚焦展示某App的上游和下游:(只展示某app的上游和下游,用于拓扑节点特别多的情况)
with 'couponcenter-service-toc' as target_app,
'2023-04-25 00:00:00' as start_time,
'2023-04-25 00:00:00' as end_time,
'http://www.xiaohongshu.com/api/store/jpd/claim' as entry_list
SELECT
downstream_app,
upstream_app,
downstream_service,
upstream_service,
sum(count) AS total,
sum(total_duration) / sum(count) AS avg_duration,
max(max_duration) AS max_duration,
sum(error) AS error,
min(examplar) AS examplar
FROM RPC_statistics_distributed
where entry in (entry_list)
and time BETWEEN start_time
and end_time
and downstream_app= target_app
GROUP BY
downstream_app,
upstream_app,
downstream_service,
upstream_service
SETTINGS allow_experimental_projection_optimization = 0,
force_index_by_date=1
union distinct -- 这里union两个字查询,避免使用or。使用or则只能走通用排除搜索
SELECT
downstream_app,
upstream_app,
downstream_service,
upstream_service,
sum(count) AS total,
sum(total_duration) / sum(count) AS avg_duration,
max(max_duration) AS max_duration,
sum(error) AS error,
min(examplar) AS examplar
FROM RPC_statistics_distributed
where entry in (entry_list)
and time BETWEEN start_time
and end_time
and upstream_app= target_app
GROUP BY
downstream_app,
upstream_app,
downstream_service,
upstream_service
SETTINGS allow_experimental_projection_optimization = 0,
force_index_by_date=1
查找app的entry:
通过 _partition_id 显示指定要查的分区,而不是指定时间范围(会走通用排除搜索,性能较差)
SELECT
downstream_app,
downstream_service,
groupUniqArray(`entry`) as entryList
from RPC_statistics_distributed
where downstream_app='jupiter-gateway-default'
-- and downstream_service='[POST]/api/store/jpd/claim'
and _partition_id='20230421' ---- 根据搜索条件手动指定分区
group BY
downstream_app
,downstream_service
settings use_skip_indexes=0, force_optimize_projection=1;
模糊搜索entry:
通过 _partition_id 显示指定要查的分区,而不是指定时间范围(会走通用排除搜索,性能较差)
select distinct entry
from RPC_statistics_distributed
where _partition_id = #{partitionId}
and entry like concat('%',#{input},'%')
排序键选择?(time, entry) or (entry, time)
我们的where过滤条件中肯定会有time和entry,所以排序键中一定会有这两个字段,需要决策的是把哪个字段放在前面?我进行了一些对比实验。
在介绍实验结果前先说一些前置知识:**Clickhouse会对分区键中datetime等时间类型的字段自动设置Minmax索引,并且在查询时自动地使用该Minmax索引。**这大概是基于写进clickhouse的数据大部分是事件、行为、时序数据,本身就是按照时间排序的。Github上也有一个相关的Issue:ReadFromMergeTree use MinMax index before Partition key to filter part,ClickHouse作者也有相关解释。
下面的实验中会看到,无论time在entry的前后,查询过程中,都会先根据time的minmax索引过滤data part,而后进行“通用排除搜索”或者“二分查找”。可参见:force_index_by_date
排序键Order By time, entry的查询
- 先根据time的minmax索引过滤data part
- 再进行通用排除搜索
性能较差
<Debug> executeQuery: (from [::1]:52053) select downstream_app, upstream_app, sum(count) as total, sum(total_duration) / sum(count) as avg_duration, max(max_duration) as max_duration, sum(error) as error from RPC_statistics_time where entry in ('[GET]/rpc') and time BETWEEN '2023-03-31 00:00:00' and '2023-04-01 00:00:00' group by downstream_app, upstream_app (stage: Complete)
<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "(entry IN ('[GET]/rpc')) AND (time >= '2023-03-31 00:00:00') AND (time <= '2023-04-01 00:00:00')" moved to PREWHERE
<Trace> ContextAccess (default): Access granted: SELECT(entry, time, downstream_app, upstream_app, count, total_duration, max_duration, error) ON cat.RPC_statistics_time
<Trace> InterpreterSelectQuery: FetchColumns -> Complete
<Debug> cat.RPC_statistics_time (19fd4510-15f2-401b-b4be-82d0ac9617c8) (SelectExecutor): Key condition: (column 1 in 1-element set), (column 0 in [1680192000, +Inf)), and, (column 0 in (-Inf, 1680278400]), and
<Debug> cat.RPC_statistics_time (19fd4510-15f2-401b-b4be-82d0ac9617c8) (SelectExecutor): MinMax index condition: unknown, (column 0 in [1680192000, +Inf)), and, (column 0 in (-Inf, 1680278400]), and
<Trace> cat.RPC_statistics_time (19fd4510-15f2-401b-b4be-82d0ac9617c8) (SelectExecutor): Used generic exclusion search over index for part 20230331_1_1_0 with 1 steps
<Debug> cat.RPC_statistics_time (19fd4510-15f2-401b-b4be-82d0ac9617c8) (SelectExecutor): Selected 1/1 parts by partition key, 1 parts by primary key, 1/1 marks by primary key, 1 marks to read from 1 ranges
<Trace> cat.RPC_statistics_time (19fd4510-15f2-401b-b4be-82d0ac9617c8) (SelectExecutor): Spreading mark ranges among streams (default reading)
<Trace> MergeTreeBaseSelectProcessor: PREWHERE condition was split into 1 steps: "and(in(entry, '[GET]/rpc'), greaterOrEquals(time, '2023-03-31 00:00:00'), lessOrEquals(time, '2023-04-01 00:00:00'))"
<Trace> MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20230331_1_1_0, approx. 57 rows starting from 0
<Trace> AggregatingTransform: Aggregating
<Trace> Aggregator: Aggregation method: serialized
<Trace> AggregatingTransform: Aggregated. 57 to 3 rows (from 2.01 KiB) in 0.003821 sec. (14917.561 rows/sec., 524.96 KiB/sec.)
<Trace> Aggregator: Merging aggregated data
<Trace> Aggregator: Statistics updated for key=6790973410114822949: new sum_of_sizes=3, median_size=3
<Debug> executeQuery: Read 57 rows, 3.23 KiB in 0.007688 sec., 7414.151925078043 rows/sec., 420.20 KiB/sec.
<Debug> MemoryTracker: Peak memory usage (for query): 1.63 MiB.
<Debug> TCPHandler: Processed in 0.008313 sec.
排序键Order By entry, time的查询
- 先根据time的minmax索引过滤data part
- 再进行二分查找
性能较好
<Debug> executeQuery: (from [::1]:52053) select downstream_app, upstream_app, sum(count) as total, sum(total_duration) / sum(count) as avg_duration, max(max_duration) as max_duration, sum(error) as error from RPC_statistics where entry in ('[GET]/rpc') and time BETWEEN '2023-03-31 00:00:00' and '2023-04-01 00:00:00' group by downstream_app, upstream_app (stage: Complete)
<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "(entry IN ('[GET]/rpc')) AND (time >= '2023-03-31 00:00:00') AND (time <= '2023-04-01 00:00:00')" moved to PREWHERE
<Trace> ContextAccess (default): Access granted: SELECT(entry, time, downstream_app, upstream_app, count, total_duration, max_duration, error) ON cat.RPC_statistics
<Trace> InterpreterSelectQuery: FetchColumns -> Complete
<Debug> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Key condition: (column 0 in 1-element set), (column 1 in [1680192000, +Inf)), and, (column 1 in (-Inf, 1680278400]), and
<Debug> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): MinMax index condition: unknown, (column 0 in [1680192000, +Inf)), and, (column 0 in (-Inf, 1680278400]), and
<Trace> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Running binary search on index range for part 20230331_1_127_22 (2 marks)
<Trace> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Found (LEFT) boundary mark: 0
<Trace> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Found (RIGHT) boundary mark: 2
<Trace> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Found continuous range in 2 steps
<Debug> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Selected 1/1 parts by partition key, 1 parts by primary key, 1/1 marks by primary key, 1 marks to read from 1 ranges
<Trace> cat.RPC_statistics (6af15a2a-5f3f-449d-ba0b-d15b535e4000) (SelectExecutor): Spreading mark ranges among streams (default reading)
<Trace> MergeTreeBaseSelectProcessor: PREWHERE condition was split into 1 steps: "and(in(entry, '[GET]/rpc'), greaterOrEquals(time, '2023-03-31 00:00:00'), lessOrEquals(time, '2023-04-01 00:00:00'))"
<Trace> MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20230331_1_127_22, approx. 57 rows starting from 0
<Trace> AggregatingTransform: Aggregating
<Trace> Aggregator: An entry for key=7368268749689958556 found in cache: sum_of_sizes=6, median_size=1
<Trace> Aggregator: Aggregation method: serialized
<Trace> AggregatingTransform: Aggregated. 57 to 3 rows (from 2.01 KiB) in 0.000821 sec. (69427.527 rows/sec., 2.39 MiB/sec.)
<Trace> Aggregator: Merging aggregated data
<Trace> Aggregator: Statistics updated for key=7368268749689958556: new sum_of_sizes=3, median_size=3
<Debug> executeQuery: Read 57 rows, 3.23 KiB in 0.00241 sec., 23651.45228215768 rows/sec., 1.31 MiB/sec.
<Debug> MemoryTracker: Peak memory usage (for query): 1.63 MiB.
<Debug> TCPHandler: Processed in 0.002968 sec.
通用排除搜索和二分查找的区别可以参考:ClickHouse主键索引最佳实践 | ClickHouse Docs
结语
本文介绍了Entry级别拓扑及性能指标计算的方案。方案包括使用ClickHouse进行相关的聚合,以entry作为标签,生成上下游调用拓扑和上下游调用性能指标。文章详细介绍了方案的架构、方案简介、详细方案和方案执行,并提供了DDL、测试数据集和测试结果。